Windows Startup errors and 0x0000225 Error
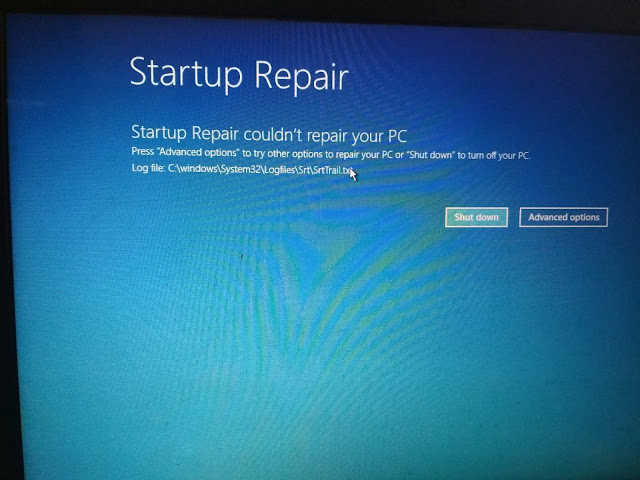
My main motto is to repair the windows with my data saved. literally, I have tried the possible to solve the above error but I couldn't at initial phases. I have opened cmd from troubleshooting option->advanced option->cmd(you can come to troubleshooting option by pressing F1 or F8 button simultaneously with the power button). you can check by pressing F2 with power(boot manager and system check) and F12 button (one-time boot menu). after entering cmd typed bootrec /rebuildbcd, The bootrec command will search for Windows installations not included in the BCD and then ask you if you'd like to add one or more to it. then you may get a result of either installation 0 or 1 if 1 press yes to add and Since the BCD store exists and lists a Windows installation, you'll first have to remove it manually and then try to rebuild it again. At the prompt, execute the bcdedit command as shown and then press Enter ...